




编者按:本文来自微信公众号 硅星人Pro(ID:Si-Planet),作者:王兆洋,创业邦经授权发布。
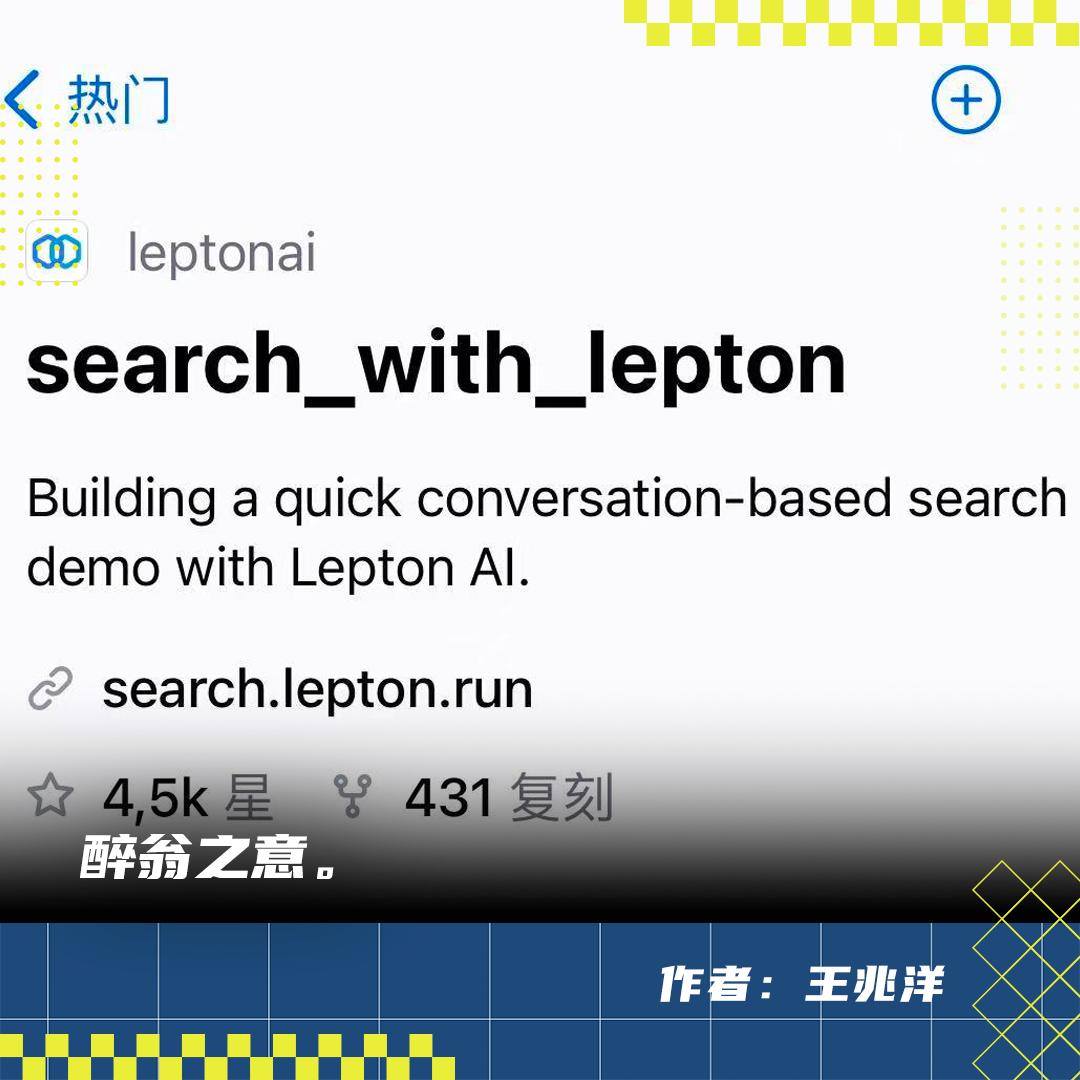
500行代码VS估值5亿
1月25日,自从宣布创业后就备受社区瞩目的贾扬清,在推特上展示了一个对话式搜索引擎的demo。
这个demo基于他创办的LeptonAI提供的框架,“只用500行python 代码”就开发完成。在邀请大家体验同时,贾扬清也表示后续计划把代码开源。在介绍Lepton Search的一系列推特里,他还艾特了Perplexity——估值已经达到5.2亿的当红对话式搜索公司,并表示受到他们优秀产品的启发。
而这也很快吸引来Perplexiyt的注意,但引来的并不是什么好话。
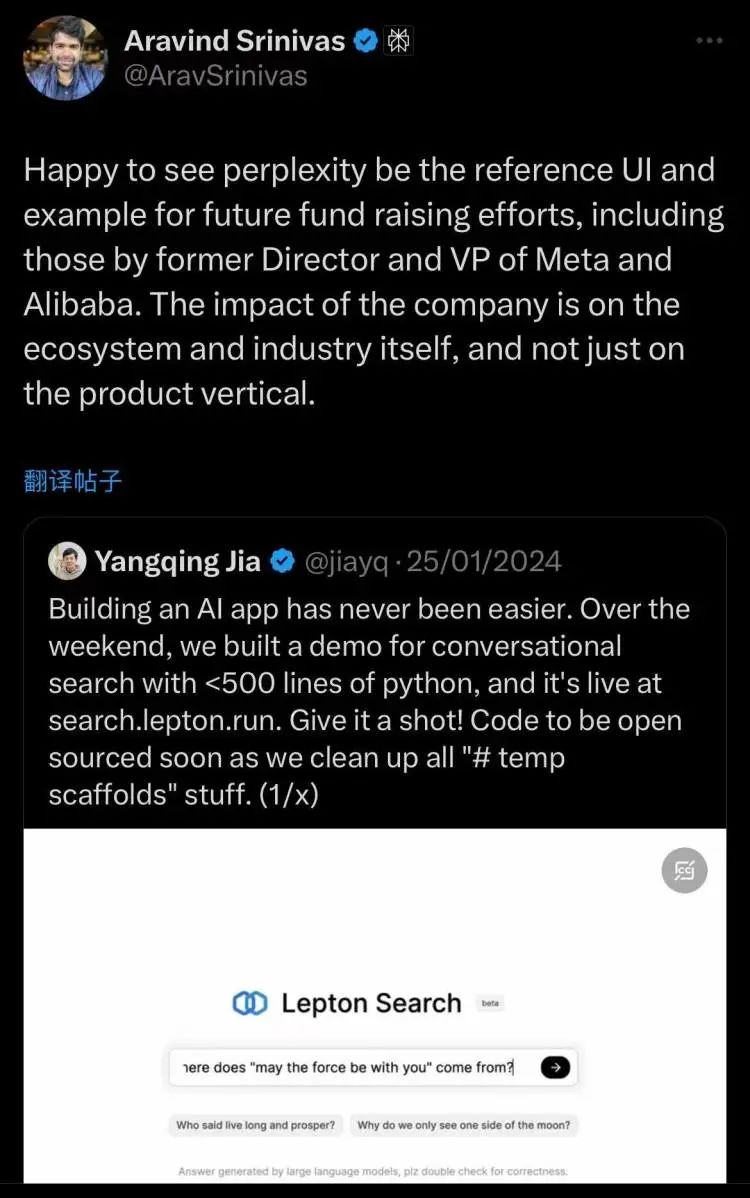
其创始人Aravind Srinivas在推特上很快转发贾扬清的推特并表示:“太棒了,看到 Perplexity 成为一些威廉希尔中文网站 动作的参照物,包括前 Meta 和阿里巴巴高管都这样做。这说明 Perplexity 的影响力不局限于产品本身,而是辐射到了整个科技生态和行业发展,令人振奋!”
翻译过来就一句话:Lepton为了威廉希尔中文网站 而抄了我Perplexity尊贵的前端代码。
而这条推特下面不乏煽风点火的评论,有人说Aravind你说的真委婉,这不就是抄袭了。但也有人指出,Aravind是反应过度,Lepton根本不是个做搜索的公司,人干嘛要盯着你借鉴。
贾扬清也迅速回应,感谢了对方“友好的评论”,然后立刻表示咱们开源见。
之后加速写代码,居然一个周末不到真就把代码开源了。
然后这500行代码在周日上线Github,一天后拿到Githhub热榜第一,第二天继续热榜。星星数不断增长,目前三天已经有了4500颗星星。

而从人们的讨论看,有人已经基于它拿到了一些黑客松冠军,它还被一款聚焦开发者版的Perplexity产品集成,其CEO夸赞这给自己带来速度大幅提升。许多体验和对比了Lepton和Perplexity的用户也夸赞了Lepton的体验。而且它还在不停迭代功能,两天不到,贾扬清和团队成员就给它增加了包括中文在内的多语言支持,把对话结果分享到推特和Facebook的功能,以及更多的API合作。
简单体验它后,我发现它确实用户界面更加简洁,速度也快很多。当然,它的功能整体也更简单,比如在每一次回答后,它就结束,再次输入开启的是新一轮回答,而非持续的对话。包括提问的长度识别,中文的识别等一些小bug也依然存在。
但他显然打破了我对Perplexity的一部分滤镜。
Perplexity的护城河被捅破了?
在开源代码后,贾扬清不忘再次艾特Aravind,表示期待合作,可以让对方体验一下真正“快速,云原生和用户体验友好的平台”。但这一次Aravind没再说什么奇怪的话。
事实上这500行代码以一种最粗暴的方式把所谓十几年来第一次能挑战谷歌的创新——对话式搜索的真实技术含量展示了出来。
从代码入手看一看,它一共就是几个步骤:1.获取查询,说白了就是得到用户输入的文字、2.抓取用户输入关键字相关的搜索页面、3.解析网页文本、4.基于文本构建提示词、5.把提示词递交给大语言模型、6.把大语言模型生成的结果返回给用户。
当然它还有些具体区别,比如搜索的来源——是使用Bing或Google的API,还是使用一个自己的数据库;背后大模型上的选择,是Mistral 还是Llama这些开源的,还是直接使用OpenAI的API,或像Perplexity还有自己的几款模型供选择;以及大模型在其中起作用的方式,是直接让它根据需求生成回答,还是经过一定的Prompt优化。
不过这样看起来你很快会明白,它本质上是关于更好使用别人API的技术。
也就是说,这一切还是建立在传统搜索引擎提供的检索能力之上——想要替代Google的Perplexity是建立在Google的API之上的。它们本质上属于RAG技术的应用,只不过,R更多来自对其他人API的系统性掌握,而G似乎可以更多归功于自己的能力。贾扬清则表示,他在开发过程里发现在RAG里,R(检索)比G(生成)的重要性更大。这样看来,目前Lepton Search的demo之所以一开始没有做多轮对话的能力,也似乎因为这个思路。展示R的能力更加重要。
Perplexity同样沿着相似的技术思路,而在一些技术人士看来,他们的根源可能来自一篇Google和OpenAI合作的论文——是的,今天看起来可能不再可能一起写论文的两家公司,最后一次合作是对话式搜索的技术原理。
在这篇《FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation》的论文里,他们提出了一种FreshPrompt的技术思路,也就是为了解决预训练模型对正在发生的事情的无知,要把它与实时搜索能力结合,而结合的方法是通过提供一种Prompt,这种Prompt本身是在按照发布日期,关键信源等各种要素来为大模型提供上下文信息,并通过一组优化的Prompt来引导和改善大模型生成更实时更好的回答。
这种技术思路其实也在指向R的重要性可能大过G。
Perplexity的网页版事实上诞生于这个论文之前,但据一些研究它产品逻辑的人表示,这个论文提出的方法也被用到后来Perplexity迭代后的产品中。
而只要看看这张论文里给出的prompt示意图,这种技术方案之下,前端长成什么样最终似乎就是一个大概率的雷同。

说了这么多,其实你会发现,如果换成一个其他的基于“别人”的API和大模型能力,以及公开的论文给出的技术路线而开发的应用,可能这“抄袭”的指责只会让人一笑而过。Perplexity的指责似乎也是一样的事情,贾扬清的500行代码成了破解独角兽身份带来的技术幻觉最好的解药。
醉翁之意
但没人否认的是,Perplexity依然是一款好产品。
然而一款充满新设计的产品的好,在于功能体验的量级上的领先,它来自对一整个系统的好品味与一个个细节积攒起来的优化。对Perplexity来说,对大模型和召回技术的理解,以及它们与应用的结合才是它快速成功的关键。而不在于一个单点的而且事实上也并不新鲜的概念。
在把理念通过简洁的前端实现后,perplexity真正抓住用户的是对产品的打磨进而将对话能力与强大搜索引擎的准确性相结合。这背后是各种细节,品味,经验积累的最终结果。因此,它的护城河必然和时间成正比,从今天人们对它的好评也能看出——速度快,体验丝滑,都是最朴素的感知,也是最容易替代的感知,因此在面对一个速度甚至更快的Lepton开源产品demo时,弦自然绷紧了。
而这也带来整件事里真正有意思的地方:Perplexity暗示Lepton是抄袭其实在揣着明白装糊涂。这种做法的一个表面上的作用,自然是“掩盖”上面讲的技术门槛并不高这件事。而除此之外,装糊涂其实还有更重要的理由。
贾扬清在去年离开阿里后,创业初期其实十分低调。但这名开发了Caffe,核心参与了Tensorflow和Pytorch的框架大神,身经百战的原阿里副总裁,显然对自己和团队的技术能力并不低调。在9月时我在硅谷听他创业后的第一次公开分享,他已经在展示自己的Lepton服务是大模型基础框架服务里速度第一的存在。只不过,现在看起来当时Lepton仍处早期,对更多模型的适配,对算力的建设等都在解决当中。
而进入2024年,贾扬清和Lepton开始逐渐高调。这一次Lepton Search的发布像是一个转折点。这家创业公司正式开始进入战场。
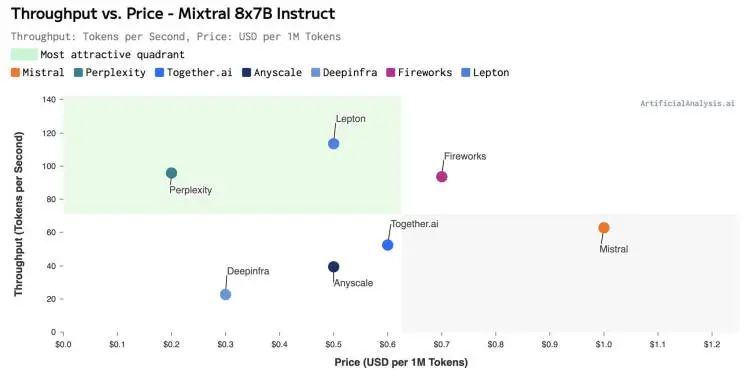
在这条Lepton Search的发布推特引发讨论的同一天,AI创业公司Martian的一份开源大模型API推理榜单发布,对多款推理产品在主要的开源模型上的推理成本、速率和吞吐量等指标做了测试,而Lepton拿下多项关键指标第一。在另一个由ArtificialAnalysis.ai发布的API推理榜单中,Lepton也拿下了Mixtral 8x7B这个模型的每秒处理Token数的第一,并且是唯一一个支持Mixtral 32k上下文窗口的服务。“它的价格也极具竞争力”,这个榜单这样说。
而在贾扬清转发的榜单图中,Lepton高高的圆圈旁边,被它超过的一个小圆圈正是Perplexity。
是的,Perplexity才不只是一个应用公司。
在Perplexity的对话搜索产品之外,Perplexity Lab其实和Lepton一样,也是一个API推理服务商,比如最近刚发布的CodeLlama-70B-Instruct,就可以购买Perplexity Lab的API来直接使用,这也是最近Perplexity真正在发力的重点,它的社交媒体等账号在大力推广的是这个服务。
相比Perplexity这个搜索应用,Lepton无疑直接冲击的是后面这部分的付费用户。
这对Perplexity有多重要呢?
事实上今天的Perplexity有点挂羊头卖狗肉的意味:
用一个极具话题度(VC可以参与共谋)的toC产品吸引威廉希尔中文网站 弹药,然后补贴到API 烧钱竞赛中去。因为前者面对的是今天商业世界里最成熟的全家桶+广告的搜索商业模式,而后者则是在新周期里重演一遍被验证多次的规模效益的机会——先烧钱拿到市场份额,再提高收费。
也就是说都是关乎API,一个是成本,一个是收益。一个是被数据方控制生死的应用,一个是掘金潮里卖铲子的生意。你说拿个真正更重要呢?
而且,如果去看一看Perplexity创业初期的故事,它最早做了一款口碑不错的推特内容的搜索,后来正因为马斯克收购推特后大幅提高API价格而被迫放弃。这些经验Perplexity显然是吸取了,不想再犯一次。
所以装糊涂的第二层目的就是借着先占据的领先和C端产品的存在感发起一下进攻,骚扰一下在基础设施端未来肉眼可见必有一战的强敌。
看来所有人都意识到,在AI基础设施层面,在所谓的API框架层面,一场更持久的战争要来了。
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。





